
研究でYOLOv8を実装する機会があったので, ここでもその方法を整理する.
なお,ここではCUDAのGPUを使う場合を想定する.
そして3次元の計測を行うため, カメラはIntel RealsenseのL515を使う.
ちなみに, v8ではなくv12も共通のラベリング画像を使えるので, v8から容易にv12のモデルを作ることもできる.(ここでは対象としないが)
はじめに
YOLO v8とは何か
YOLOv8は, Ultralytics によって2023年1月10日にリリースされた物体検出アルゴリズムである[1].
YOLOはYou Only Look Onceの略称で画像を一度だけ見る(=1回のCNN処理で物体の位置と種類を同時に推定する)ことから名付けられた手法.
公式ドキュメント[1]には次のようなグラフがある.
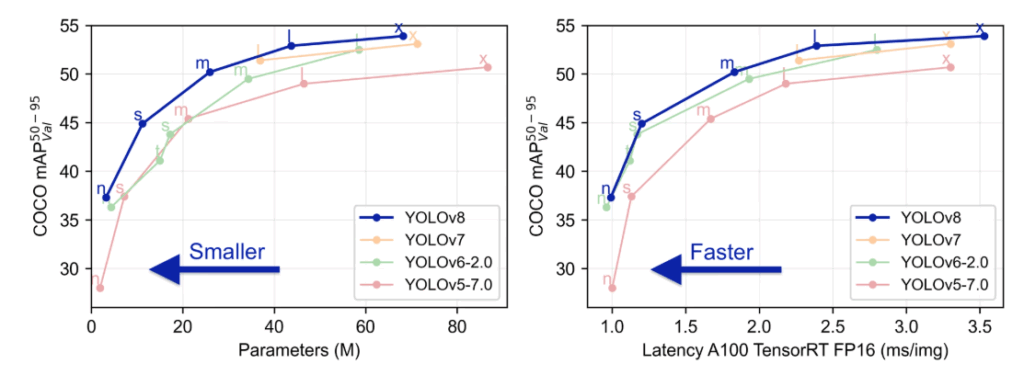
図1の左の図は, パラメータと精度の関係を示している.
パラメータとは, ニューラルネットワークの重みやバイアスなど, 学習によって最適化される値の総数を指す. Mは, 百万を意味する. パラメータ数が多いほど, モデルはより多くの情報を表現できるが, メモリ消費や計算コストが増えて, 学習や推論が遅くなる.
図中の, n,s,m,l,xは, それぞれYOLOv8のモデルサイズの種類を示しており,それぞれ, nano, small, medium, large, x-largeを意味し, 大きいくなるにつれて制度が高くなる.モバイルや組み込みに向いているのは軽いnanoになる.
一方で, 図1の右の図は, 推論速度と精度の関係を表す.
横軸の意味は, NVIDIA A100 GPU上で, 1枚の画像を推論するのにかかる時間(ミリ秒)を表す.
総じてこの図からYOLO v8が以前のバージョンと比較して推論速度も推論精度も向上したことが読み取れる.
この記事で実現すること
本記事で目指すのは, モデルを学習させ, 所望の物体の運動を計測することである.
ここでは筆者がペンを持ち, そのペンの運動を記録する.
具体的にはバウンディングボックスを作り, その範囲の深度情報の中央値を代表値として, ペンの動作を記録することを目指す.
(用途は研究で使う)
対象読者
・YOLO の実装をしたことない人
・初めて物体認識を触る人
・物体の運動を計測したい人
環境構築
使用PCのスペック
使用PC環境
- OS:Windows 10
- CPU: Intel Core i7-6700(第6世代 Skylake, 4コア8スレッド, 3.40GHz)
- GPU: NVIDIA GeForce GTX 1060(6GB VRAM)
- RAM: 16GB(2133MHz)
- ストレージ: SSD 1.16TB(使用中 443GB)
- Python:3.10.18
- PyTorch 2.5.1
- CUDA 12.1
- Ultralytics:8.3.208
Anaconda環境の作成
以下のコマンドをAnaconda Promptに入力し, 新しいYOLO v8用の環境を作る.
conda create -n 環境名Pythonのバージョンを指定したい場合は次のようにする
本記事ではPythonのバージョンを指定せずに環境を作った.
conda create -n myenv python=3.10普段Pythonの環境を意識しないため, 今回はこの環境によるエラーが多発した.
Anaconda promptで表示される環境は, 次の図2の()でしめされたものである.
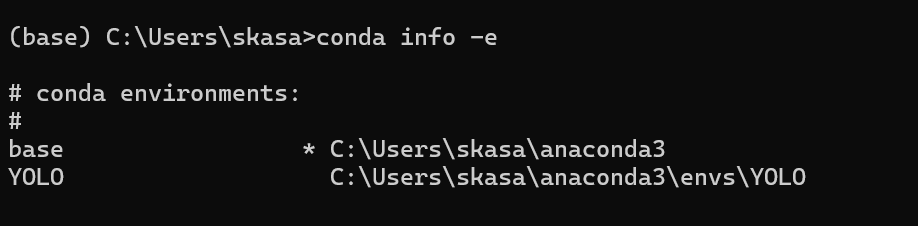
他の環境を一覧にして確認したいときは, 図3のように, 「conda info -e」で確認できる.ここでアスタリスク(*)がついたものが今動いている環境である.
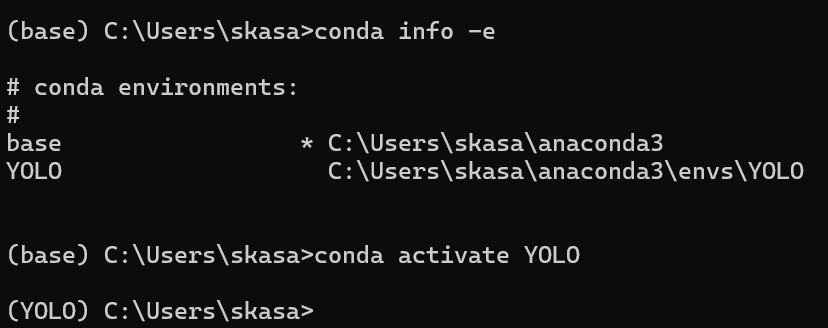
ここで仮に, YOLOのほうの環境を動かしたい場合, 図4のように「conda activate YOLO」で環境を変えられる.
一方で, このAnaconda Promptで動いている環境のままjupyter labを起動すると, その環境でJupyter labが起動する, わけではない. Jupyter labの環境は, また再度Jupyter labで選ぶ必要がある.
必要なライブラリのインストール
Ultralytics, PyTorchをインストールするために下記をAnaconda promptで実行した.
//CUDAのGPUを用いる場合
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
//新しくインストールする場合は「 -U 」は不要
pip install -U ultralytics
今回の実装で一番苦労したのはnumpyのバージョン不一致によるエラーである.元々使っているNumPyは2系であるが, Pytorchは1系を元にしているらしく, エラーになった.そこで, Numpyのバージョンを1系に落とすことで解決した.
YOLO v8の導入
検索で「https://ultralytics.com/images/bus.jpg」と検索するとバスの画像をダウンロードすることができる.このバスの画像をjupyterファイルと同じディレクトリに置く.
そして次のコードを実行する.
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
results = model.predict(source="bus.jpg", save=True)
from IPython.display import Image, display
display(Image(filename="runs/detect/predict/bus.jpg"))
すると次のような結果が出力される.
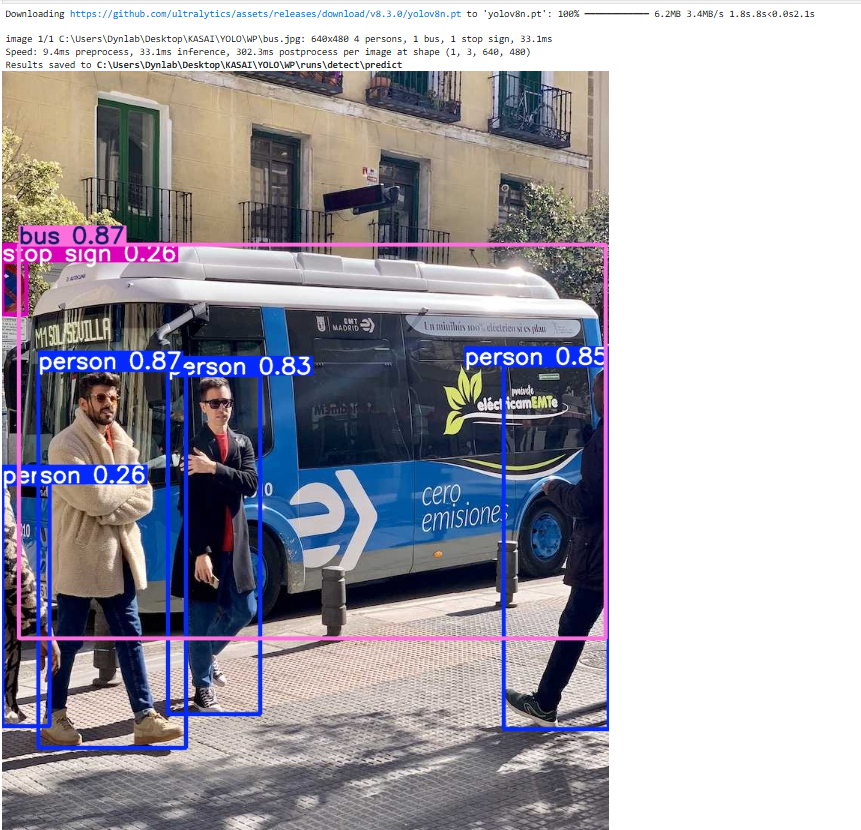
そしてディレクトリに「yolov8n.pt」ファイルが生まれている.
これはYOLOにおいて,最も重要な部分で訓練した結果得られた重みやバイアスが保存されており, 推論に使われる. また同時に「runs」というフォルダも生まれている. このrunsの中には,「runs/detect/predict」という階層になっており,一番下には図5の認識された結果画像が格納されている.
ultralyticsが提供する訓練済みモデルは下記に示す80個の物体を認識することができる[2].
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush自作データセットの準備
前節で示した80個の物体以外を認識しようとすると自分でモデルを訓練する必要がある.
そこでここではそのための準備を行う.
ここで理解しておきたいファイルがある.
それが, ①「.pt」/②「.yaml」/③「.jpg or .png」/④「.txt」ファイルの存在である.
①のptファイルは前章でも記述したが, 学習の結果得られた重みとバイアスが保存されたファイルである.Pytorch形式で保存されており, 推論に使われる.(model = YOLO(‘yolov8n.pt’))
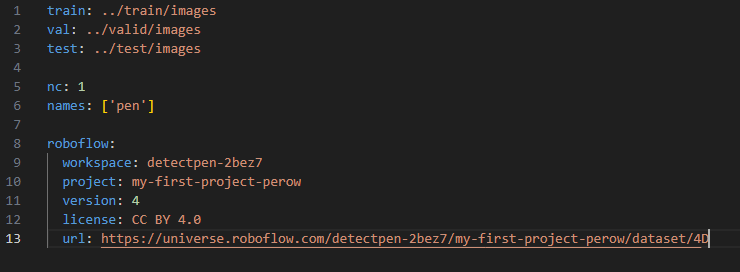
②のyamlファイルは, データセットの定義が書かれたファイルであり, どのフォルダにtrain/valid画像が入っているのか, 何クラスを学習して識別するのか, またそのクラスの名前等が入っている. これは人間でも読めるファイルである.
③のjpg, pngファイルは, 通常はtrain, val, (validation), testの3つのフォルダに分けて管理される.検証用とテスト用は役割が異なり, テスト用は最終的な性能評価にのみ使われる.
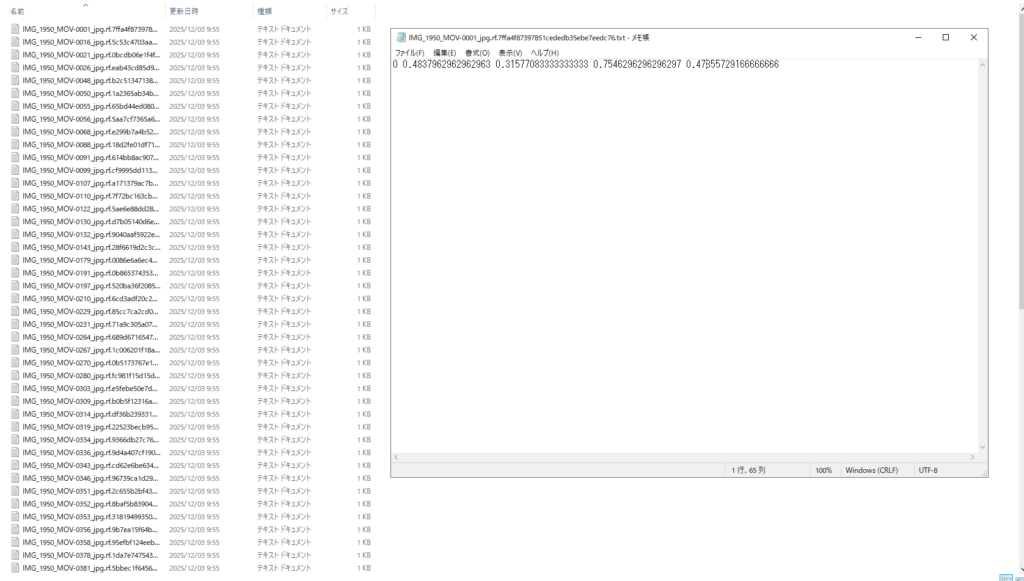
④のtxtファイルは学習用, 検証用, テスト用に用意した画像の中でどこをバウンディングボックスで囲むべきかを記述したアノテーションデータである. 具体的には,[クラス番号, x_center, y_center, width, height]が羅列されている(学習するときに実際に載せる. 図OO参照). 5つの物体(クラスではない)を学習させたい場合,1つのテキストファイルに5行書かれる. また, 座標はすべて正規化され0~1で表される. テキストファイルは, 画像ファイルと同名にする必要があり(例:bus.jpg ↔ bus.txt), この対応関係によってYOLOが自動的にラベルを読み込む.
そのため, 画像ファイルと同じ数だけ用意し, テキストファイルの名前を変更するなどして順番を変えることはできない.
イメージとしては図6のような構図である. なお, 数は適当である.

これだけの数の画像を用意し,またその画像一つ一つの物体の場所をテキストファイルで用意するのは困難であるため, これを助けるサービスがある. ここではRoboflowを使う.
動画を撮影
ここでは, 手で持つペンの動きを認識したいとする.
そこで下のような動画を1分程度撮影した(容量上4倍速にしている).
動画から画像を切り抜く
まず, Roboflowにログインする.図7のように, 新しいworkspaceを作る.

そして図8にある「New Project」を選択.
次に図9の画面から, 「Project Name」,「Annotation Group」, 「Project Type」などを選択する.
今回は「Project Type」として「Object Detection」を選択する. そして「Tool」は「Traditional」を選択する.
その次に図10のような画面になる. ここで「Select Files」から先ほど撮影した動画をアップロードする.
アップロードした動画から画像を作成するために, 図11, 図12の画面から何枚の画像を作成するかを入力する. 今回は800枚の画像を作成した.
(本来は訓練データだけで3000枚程度は必要であるらしい)
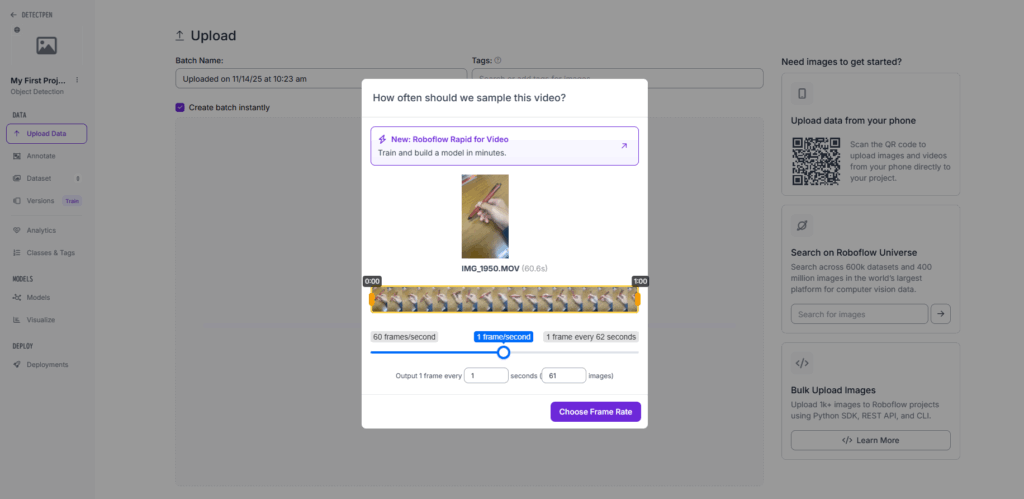
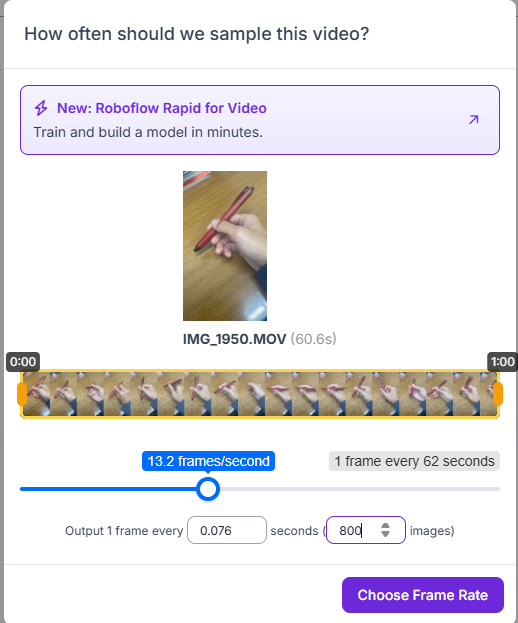
図12の「Choose Frame Rate」をクリックすると作成が始まる.
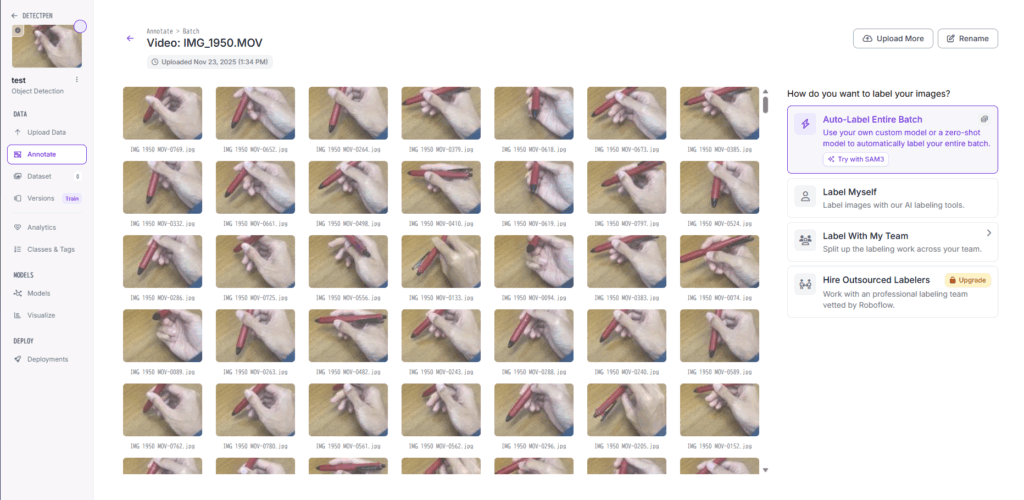
数分後に画像の切り抜きが終わり図13の画面になる.
ここで画像にラベルを付けるために , 右側の「Label Myself」を選択する.
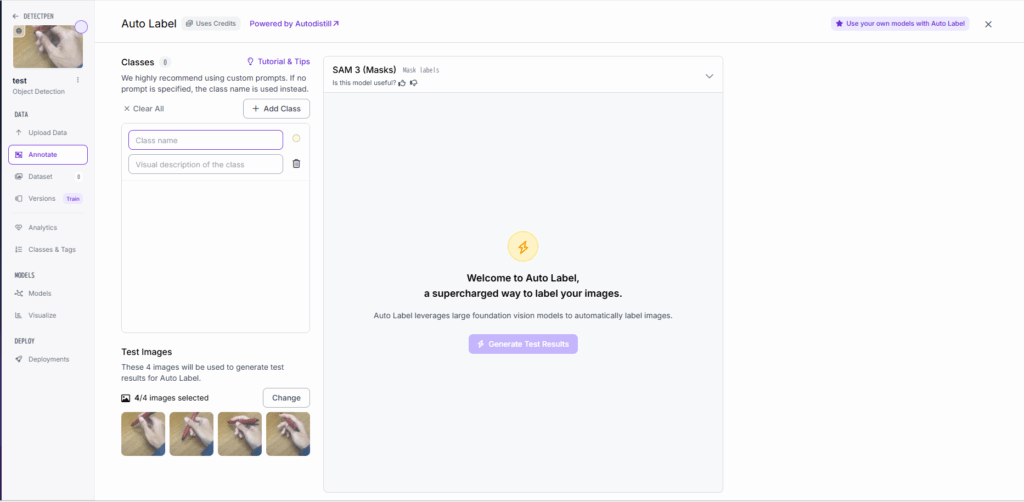
図Aから「Auto-Label Entire Batch」を選択すると次の画面となり, 何クラスを識別するのかを入力できる. そしておそらく自動でのラベリングが行われる. 500枚の画像に対し5creditが必要らしく, 無料ユーザーは月に30creditが使えるみたい.(2025/11/24 現在)
図Bより, クラスを入力する.
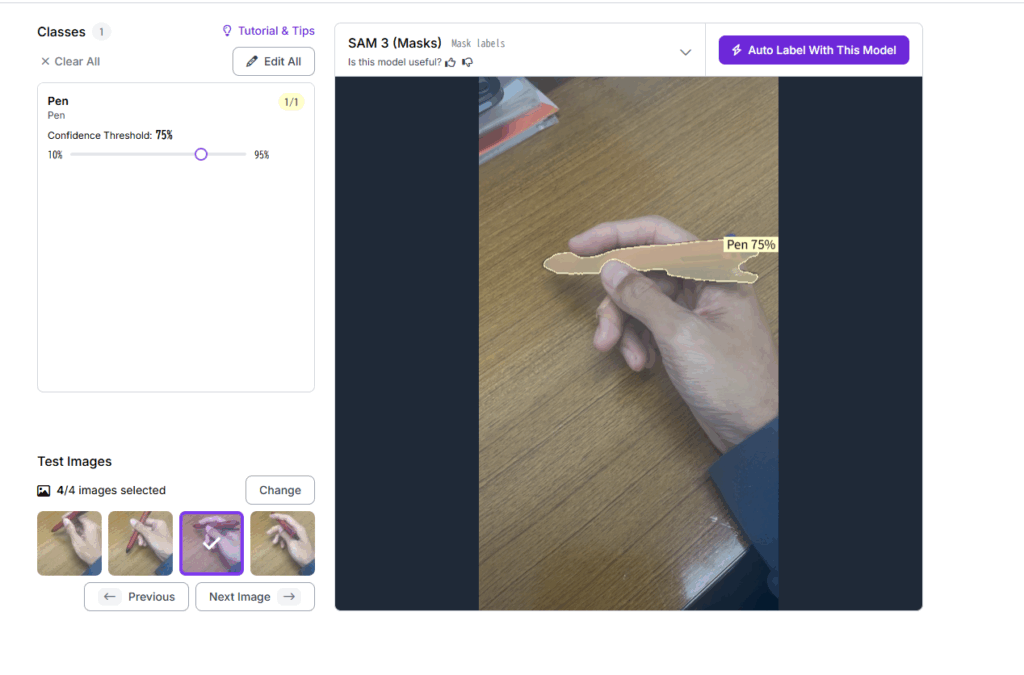
図Cにおいて, しっかりとオブジェクトを認識できているか4枚確認する. 画像を変更することもできる. Confidenceをできるだけ高いものに合わせておく.
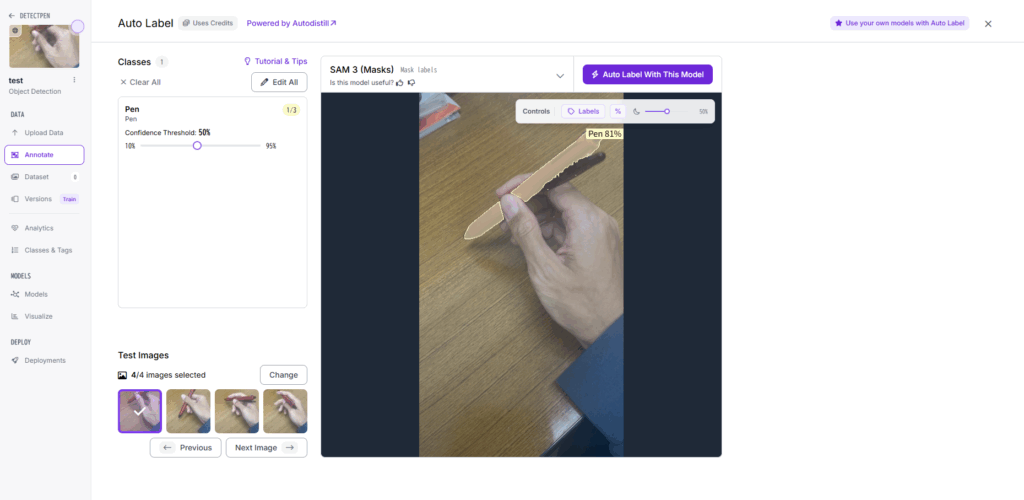
4枚問題なく認識ができたら図Dの右上の「Auto label with this model」をクリック.
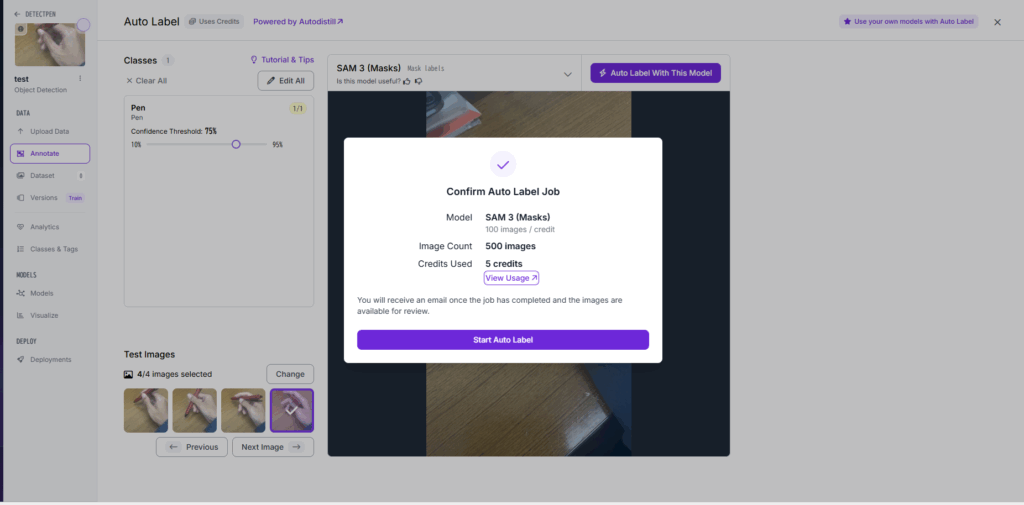
図Eより, 「Start Auto Label」を選択.クレジットを消費することに注意.
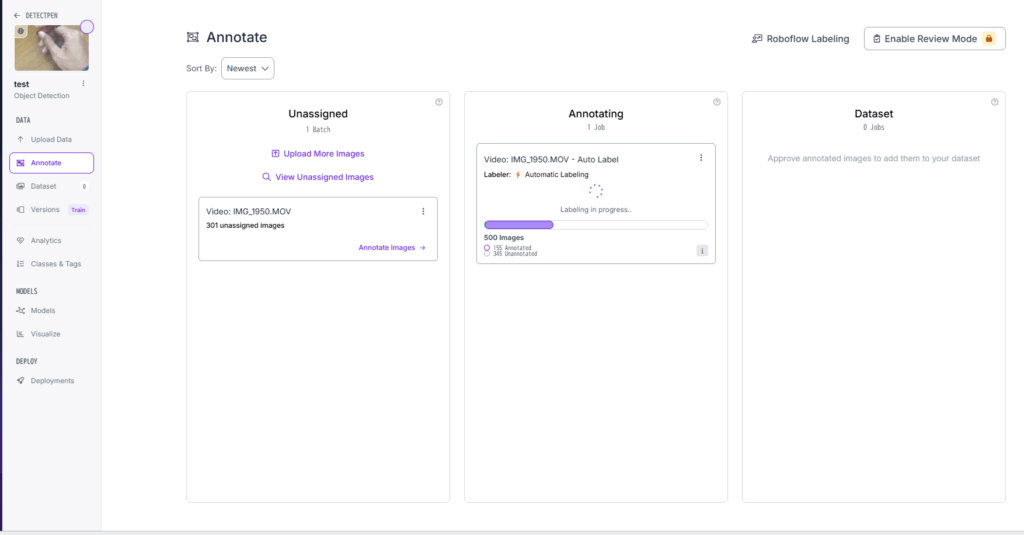
図Fの中央「Anotating」を選択.
終わったら「Review」から結果を確認する.
図Gから, 認識できていないものは手動でバウンディングボックスを使い, 「Approved」に移す.
個人的な感想だが, 図Hのような解像度で認識できていることにかなり驚いた.

ラベリングが終われば, 図Iにおいて,右上の「Add Approved to Dataset」をクリック.
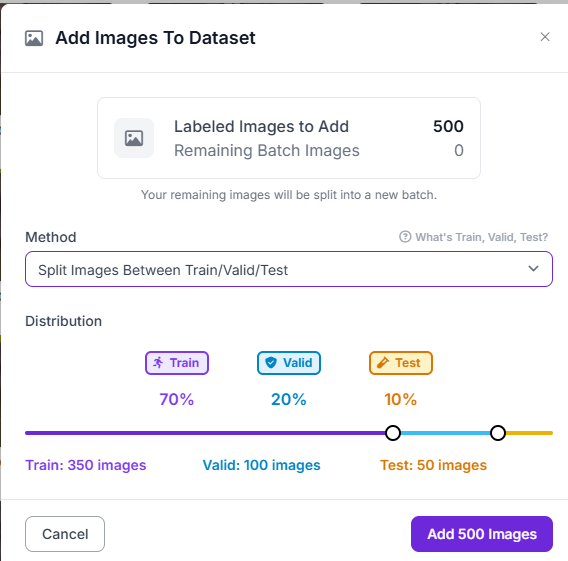
図Jにおいて, 500枚の画像を訓練, テスト, 検証に分類する.ここではデフォルトの7:2:1とした.
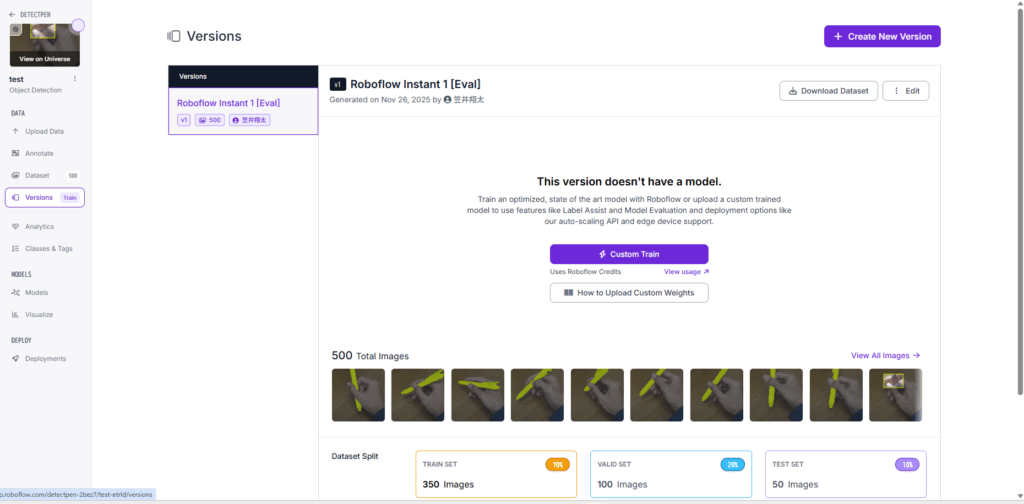
分類ができればあとはラベリングしたファイルを保存するだけだが一応訓練結果も見てみる.(これは必要ないと思う). ラベリングしたファイルを保存するには図Mから.
図Kにおいて. 「Train Model」を選択する.
図Lにおいて,「Roboflow instant Model」を選択. その後にモデルの結果が得られる.
ここから訓練データに使った画像が適切かなどを判断する.
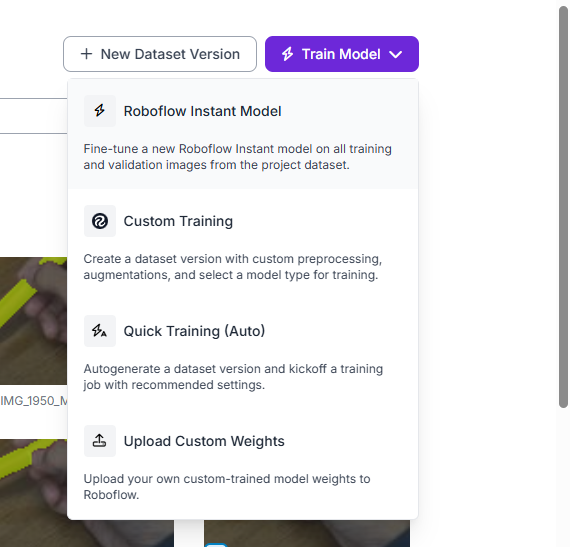
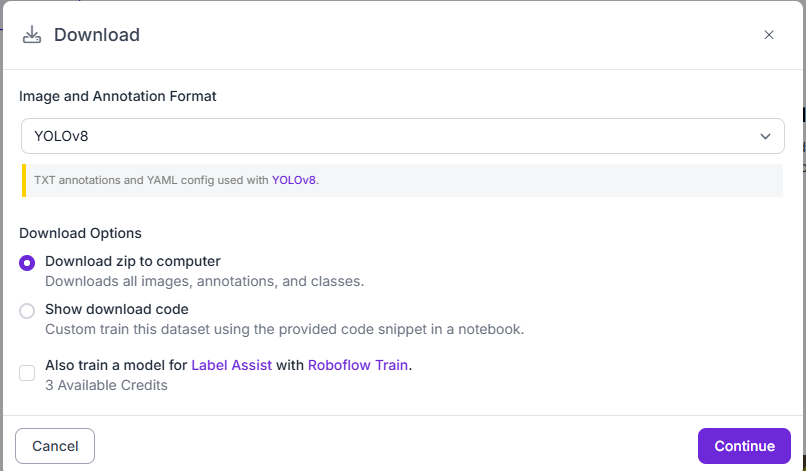
図M(Versionsの画面)において,右側にある「Downlowad Dataset」をクリック.
図Nより,画像とアノテーションのフォーマットを選択する.ここでは, 「YOLO v8」を選択.
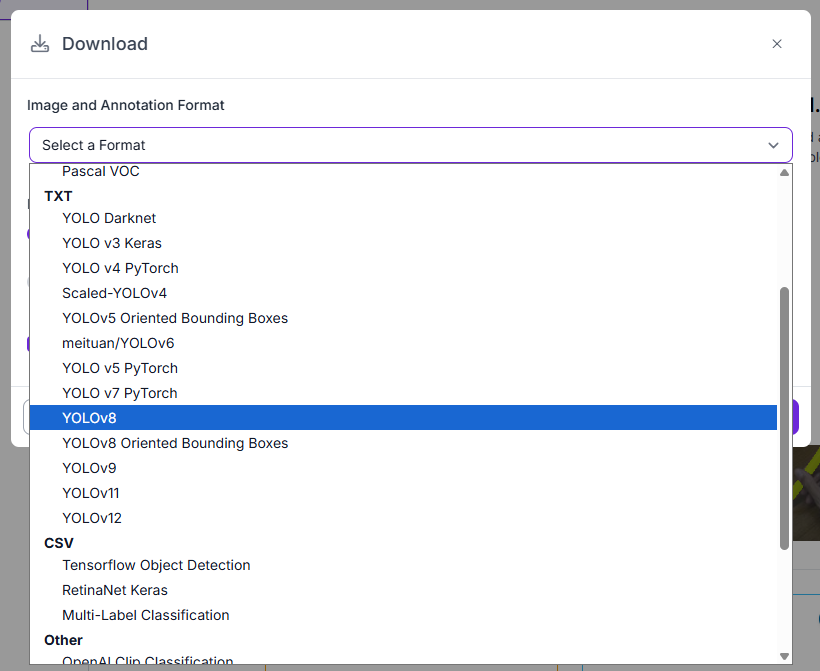
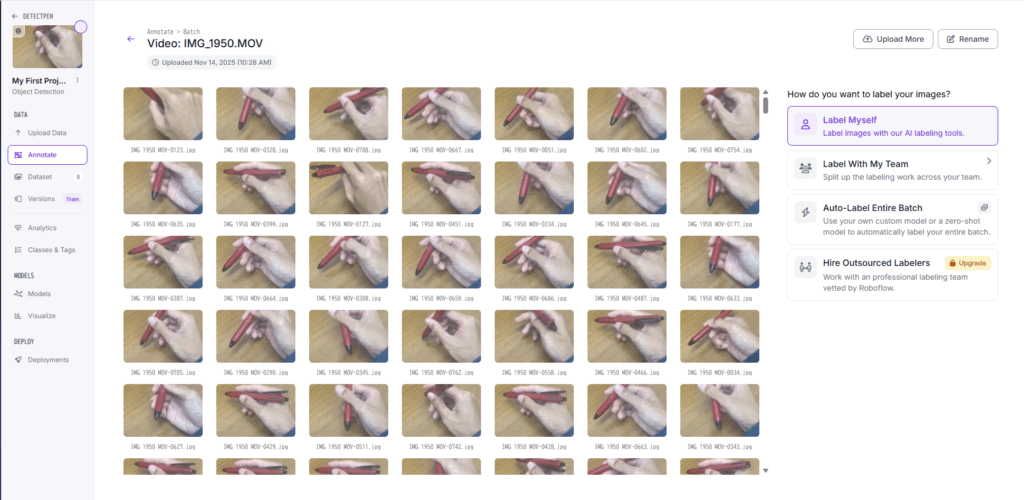
図14の画面になったら画像をクリックしてアノテーションを開始する.
画像をクリックし, 図15, 図16のようにバウンディングボックスを作る.
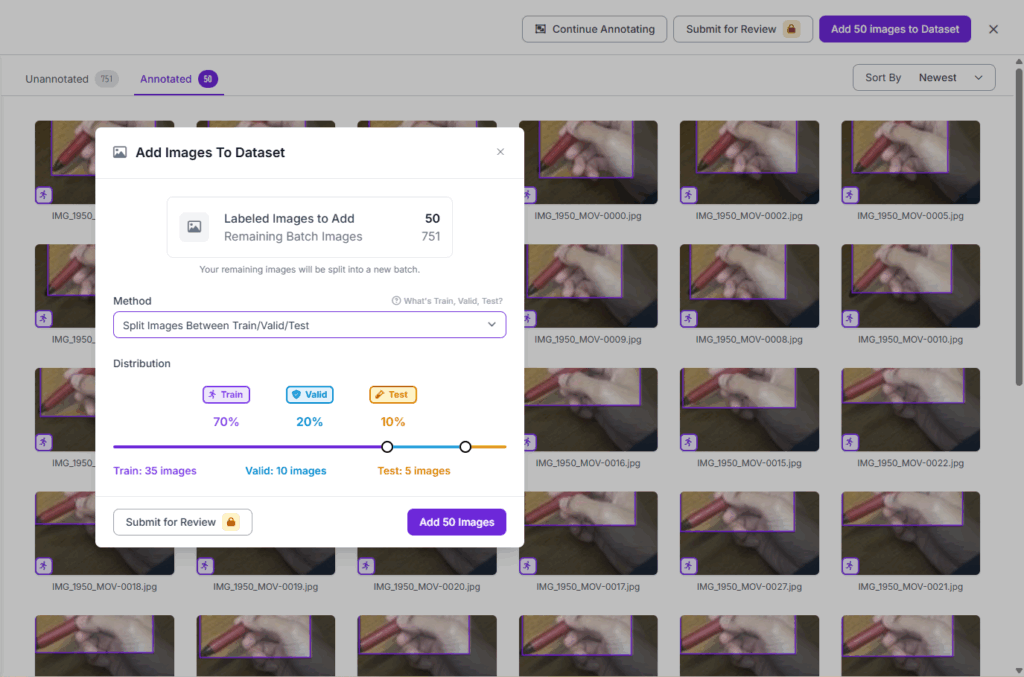
ある程度(今回は少ないが50枚程度)手動でラベリングをしたら, 図17, 右上の「Add 50 images to Dataset」を選択.
図18において, データをtrainに振るのか, test, validに振るのかを選択する画面になるが,ここではデフォルトの7:2:1とした.
画像を割り振り, 図19の右上より, モデルを訓練することができる.
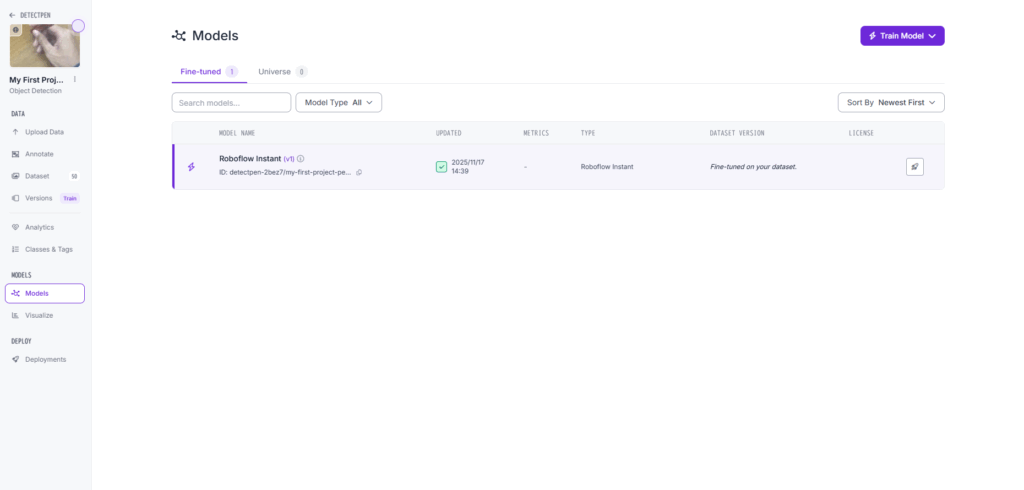
モデルの訓練が終わったらラベリングの際にそのモデルを利用することができる.
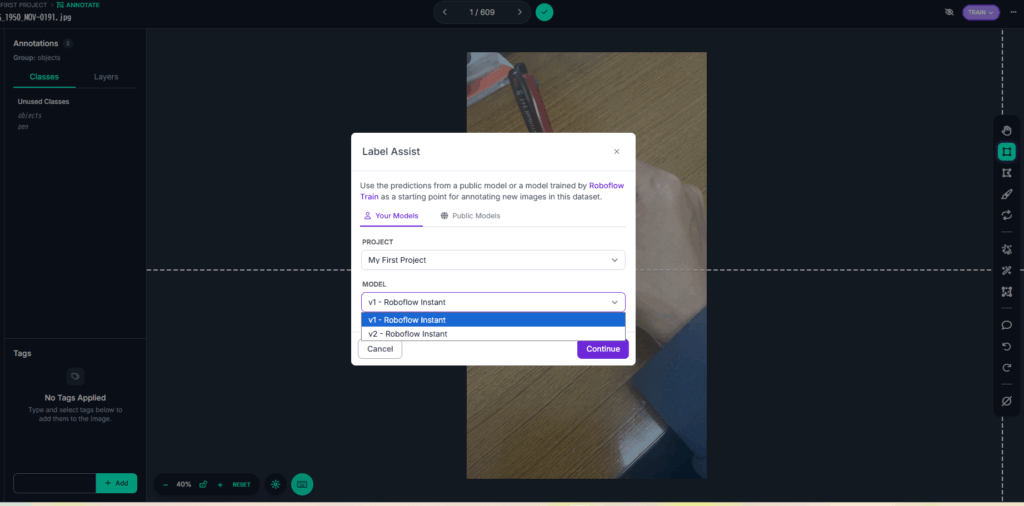
図20の画面の右で「Label Assist」から先ほど作ったモデルを選択する.
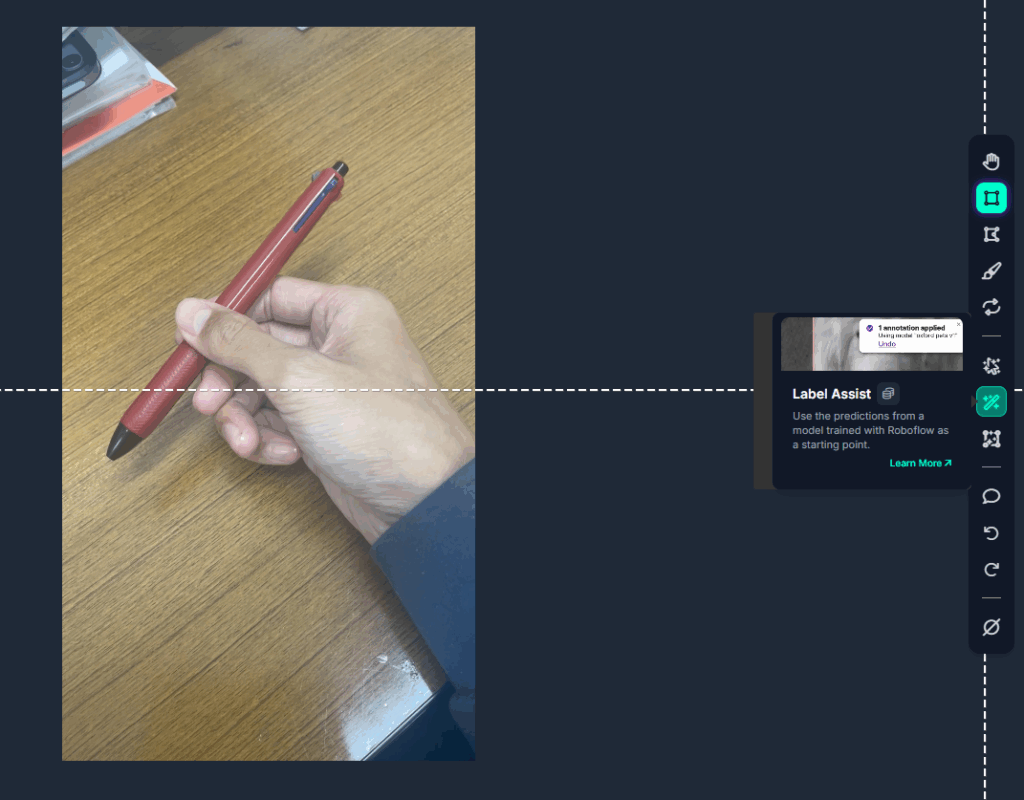
この機能を使うと, 自動でバウンディングボックスを作ってくれる.
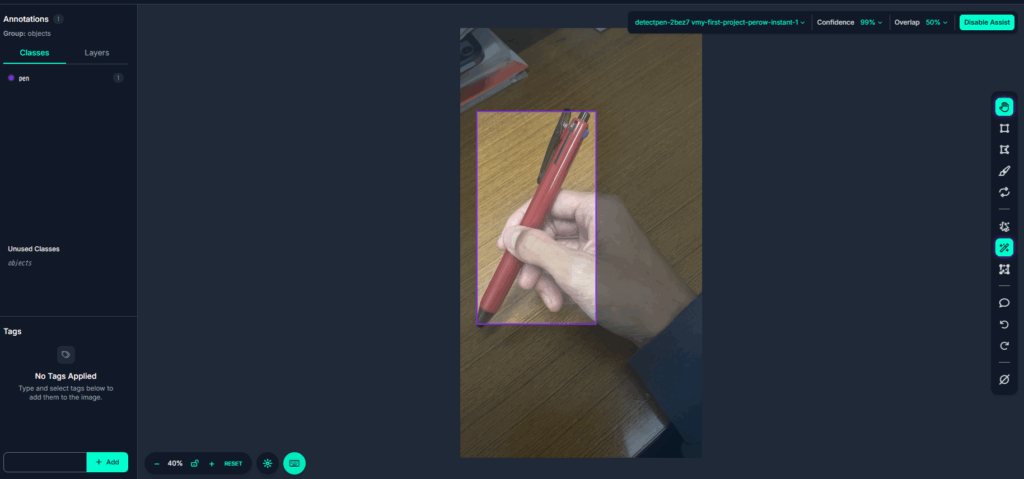
しかしたまに図21のように多めに誤認識されることがある.
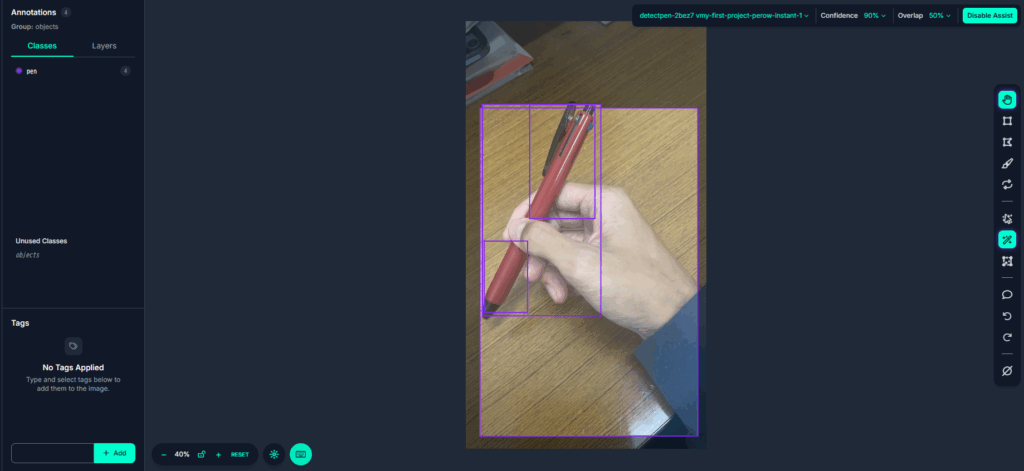
その際は図22, 図23のように, 「Confidence」の値を99%など高くすることで一つに絞ることができる.
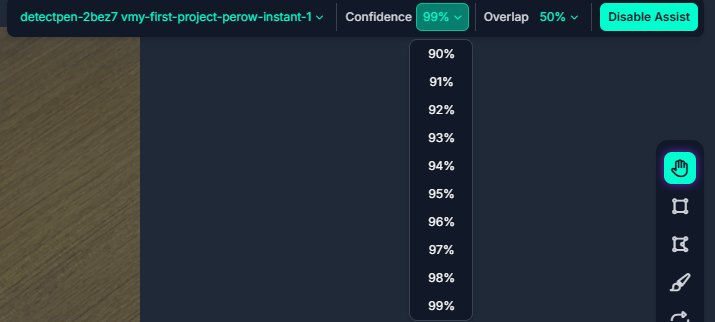
以上を繰り返し行う. なお, そのラベリング済みの画像が溜まったら, 再度モデルをアップデートできる.
図24の画面から右上の「Train Model」を選択する.
図25から, 「Roboflow Instant Model」を選択する.
訓練が終わると, 図26のように「Roboflow Instant v2」ができる.
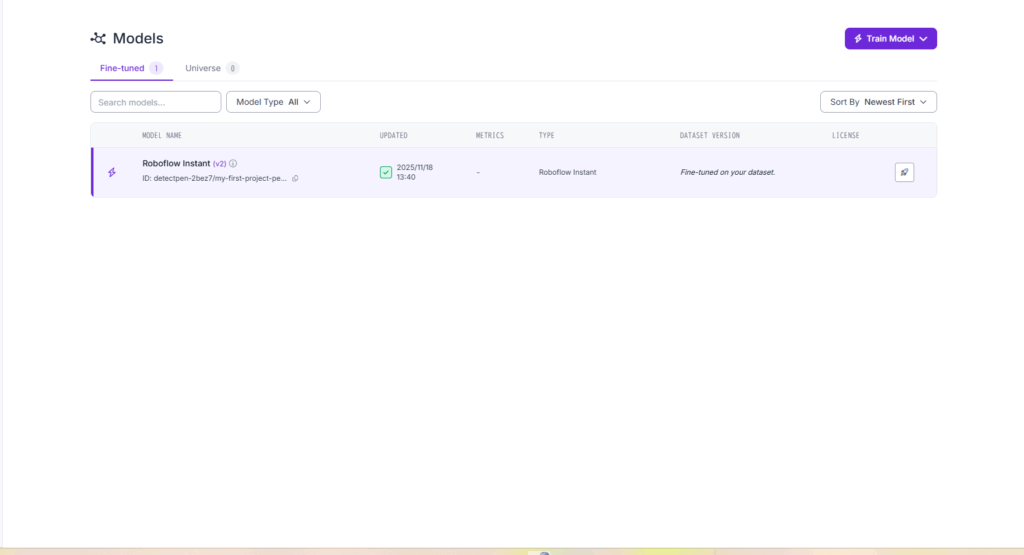
この更新したモデルは再度ラベリング時に使える. 「Label Assist」からモデルのバージョンを図26のように選択できる.
すべての画像に対してアノテーションが完了したら, その画像を使って最後にもう一度訓練を行う.
すると図27のようにVersionで, 今まで使われてきた画像が確認できる. Versionが上がるにつれて, 画像の枚数が蓄積されていることがわかる.
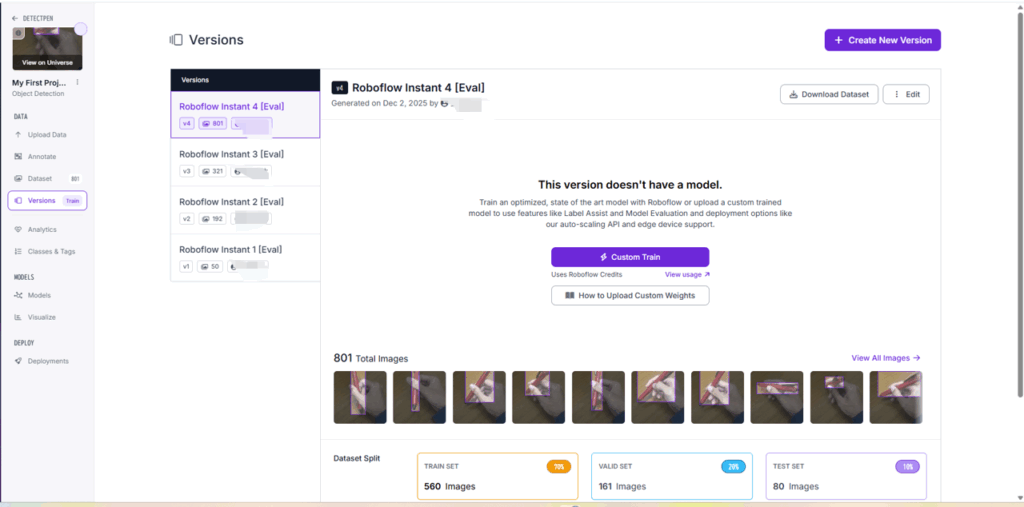
図27の「Download Dataset」から, 図28のようにダウンロードする.
「Image and Annotation Format」はYOLOv8とした.
Zipファイルをダウンロードし展開すると図29のようなファイルが得られる.
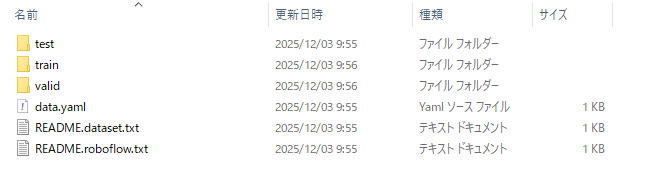
「data.yaml」の中身は図30のように, train, val, testそれぞれのファイルの位置関係を示している.
test, train, validそれぞれのファイルの中身には, labelファイルとimageファイルが存在する.
それぞれの中身は, 図31, 図32のようになっている.
上記に示した画像ファイルやラベルファイルを使って, モデルの訓練を行う.
モデルの学習
モデルの訓練は, 次のコードで行う.
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.train(
data=r"WP_Roboflow_Dataset/data.yaml",
imgsz=640,
epochs=50,
batch=16, # VRAMに応じて調整(足りなければ 8/4 に)
device=0 # GPU使用
)
上のコードを実行すると次の図33のような実行経過が確認できる.
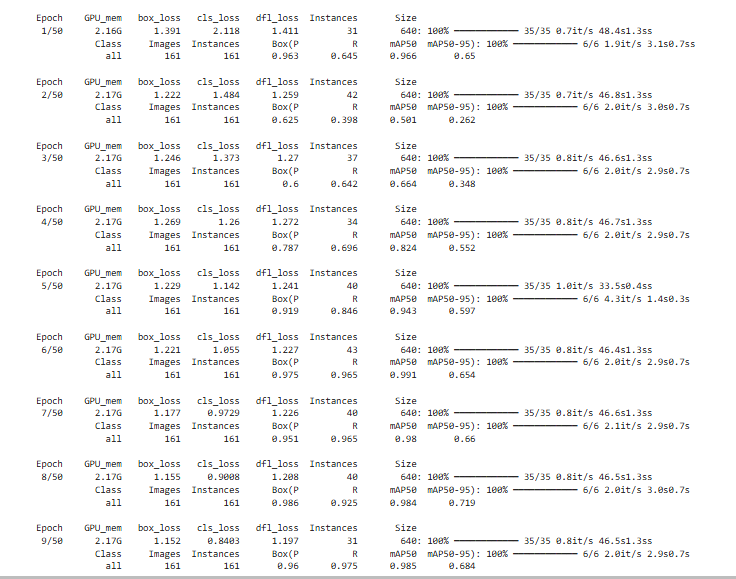
「runs」というフォルダが生まれ,その中に検証の結果やそのCSVファイルやimgファイル,そして訓練の結果得られた二つの重みファイル(best.pt, last.pt)が含まれている.
best.ptは,検証データ(validation)に対して最も精度が高かった瞬間のモデル,
last.ptは, 最終エポック(例: epochsを50としたなら50番目のエポック)の学習が終わった直後のモデルを採用している.
推論の実行
ここでは, 前章で学習した「best.pt」を用いて実際にペンを認識させ, その動作を確認した.
ここではカメラにIntel Realsense L515 を用いた.
リアルタイムに運動を推定し, その初期値からの距離や時間, FPSなどを画面に表示させ, またバウンディングボックスも表示させた.
その時の映像と初期値からの変位をCSVとして記録した.そのためのプログラムコードを次に示す.
import pyrealsense2 as rs
import numpy as np
import cv2, csv, time
from datetime import datetime
from ultralytics import YOLO
# ==== YOLOモデル ====
model = YOLO(r"runs/detect/train/weights/best.pt") # 自分の学習済みモデルに置き換え
IMGSZ = 640 #画像サイズ
CONF_THR = 0.25 #信頼度閾値
SAMPLING_PERIOD = 0.05 # 20Hz
FPS=20
# ==== RealSense初期化 ====
pipe = rs.pipeline()
cfg = rs.config()
cfg.enable_stream(rs.stream.depth, 1024, 768, rs.format.z16, 30)
cfg.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30)
profile = pipe.start(cfg)
align = rs.align(rs.stream.color)
depth_sensor = profile.get_device().first_depth_sensor()
depth_scale = depth_sensor.get_depth_scale() # 単位→m変換倍率, 深度画像の1カウントあたり、何メートルかを示し, メーカー(intel)が決めている.
# カメラ内部パラメータ(X,Y計算に使用)
intr = profile.get_stream(rs.stream.color).as_video_stream_profile().get_intrinsics()
#fx,fyは、画像の横縦方向(u,v方向)のスケールで「1m 離れた点が、画像上で何ピクセル分広がるか」を表す.cx,cyは基準となるピクセルを表す.
fx, fy, cx, cy = intr.fx, intr.fy, intr.ppx, intr.ppy
# ==== 保存用 ====
stamp = datetime.now().strftime("%Y%m%d_%H%M%S")
csv_path = f"realsense_yolov8_{stamp}.csv"
# ==== 動画保存用 ====
video_path = f"realsense_yolov8_{stamp}.mp4" # or .avi
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
# 書き出しサイズは color の実サイズに合わせる(1280x720)
VIDEO_W, VIDEO_H = 1280, 720
# 実際の記録周期は 0.05s なので 20fps にしておくのが分かりやすい
video_writer = cv2.VideoWriter(video_path, fourcc, 20.0, (VIDEO_W, VIDEO_H))
video_writer = None
def init_writer_if_needed(frame, fps):
global video_writer
if video_writer is None:
h, w = frame.shape[:2]
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
video_writer = cv2.VideoWriter(str(video_path), fourcc, fps, (w, h))
def median_xyz(depth_np, x1, y1, x2, y2, margin=0.1):
"""bbox内の有効深度から(X,Y,Z)中央値[m]を求める"""
#depth_npは深さの情報で、その形状はh*wある。
h, w = depth_np.shape
dx = int((x2 - x1) * margin)#端はノイズがあると考え、10%をdxと定義。
dy = int((y2 - y1) * margin)
x1, x2 = np.clip([x1+dx, x2-dx], 0, w-1)#bboxの中央80%が範囲外にはみ出さないための安全策。
y1, y2 = np.clip([y1+dy, y2-dy], 0, h-1)
roi = depth_np[int(y1):int(y2), int(x1):int(x2)]#80%範囲の深さ情報を抽出
mask = roi > 0
if np.count_nonzero(mask) == 0:#深度が一つもとれなかったらスキップする
return None
zs = roi[mask].astype(np.float32) * depth_scale
us, vs = np.meshgrid(np.arange(x1, x2), np.arange(y1, y2))#bboxの中の3D化をするため(1点のみなら不要)
us, vs = us[mask].astype(np.float32), vs[mask].astype(np.float32)
Xs = (us - cx) * zs / fx
Ys = (vs - cy) * zs / fy
return float(np.median(Xs)), float(np.median(Ys)), float(np.median(zs))
# ==== メインループ ====
t_start = time.perf_counter()
t_prev = t_start
prev_xyz = None
PT0=None
with open(csv_path, "w", newline="", encoding="utf-8") as f:
wcsv = csv.writer(f)
wcsv.writerow(["t_elapsed_s", "dt_s", "Xm_m", "Ym_m", "Zm_m"])
try:
while True:
# フレーム取得
frames = pipe.wait_for_frames()#wait_for_frames() は色と深度の両方が揃ったタイミングまで待機する。
aligned = align.process(frames)#深さの座標系を色の座標系に一致させる
depth_fr = aligned.get_depth_frame()#深さ情報。まだnumpyじゃない。(pyrealsense2.depth_frame型)
color_fr = aligned.get_color_frame()#色情報。まだnumpyじゃない。(pyrealsense2.video_frame型)
if not depth_fr or not color_fr: #深度(depth) か カラー(color) のどちらか一方でも欠けていたらこのループの処理をスキップして次のフレームを待つ。
continue
depth_np = np.asanyarray(depth_fr.get_data())
color_np = np.asanyarray(color_fr.get_data())
# YOLO推論(verbose=Falseは, ログの出力をしないため)color_npは1枚なので最初の[0]のみしかない
res = model(color_np, imgsz=IMGSZ, conf=CONF_THR, verbose=False)[0]
# 時間制御(20Hz)
t_now = time.perf_counter()
elapsed = t_now - t_prev
if elapsed < SAMPLING_PERIOD:
time.sleep(SAMPLING_PERIOD - elapsed)
t_now = time.perf_counter()
dt = t_now - t_prev
t_elapsed = t_now - t_start
t_prev = t_now
# バウンディングボックス処理
Xm = Ym = Zm = None
found_bbox = False
x1 = y1 = x2 = y2 = None
conf = None
if (res.boxes is not None) and (len(res.boxes) > 0):
confs = res.boxes.conf.cpu().numpy()#信頼度を抜き出してnumpyにする.array([0.83, 0.74, 0.65]) のようになる
xyxy = res.boxes.xyxy.cpu().numpy().astype(np.int32)#左上・右下の (x1,y1,x2,y2))を numpy 配列に変換.
#array([[100, 51, 300, 401],[120, 80, 261, 351],], dtype=int32)のようになる
idx = confs.argmax()#confsの中で一番大きい信頼度のインデックスを取得
x1, y1, x2, y2 = xyxy[idx] #最も信頼度の高いオブジェクトの左上と右下の座標を取得
found_bbox=True
med = median_xyz(depth_np, x1, y1, x2, y2)
if med is not None:
Xm, Ym, Zm = med
prev_xyz = med
# # 表示
# cv2.rectangle(color_np, (x1, y1), (x2, y2), (0,255,0), 2)
# cv2.putText(color_np, f"X:{Xm:.3f} Y:{Ym:.3f} Z:{Zm:.3f}",
# (x1, max(0, y1-8)), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0,255,0), 2)
# 検出なし時は前回値を保持
hold_mode=False
if Xm is None and prev_xyz is not None:
Xm, Ym, Zm = prev_xyz
hold_mode=True
# cv2.putText(color_np, f"HOLD X:{Xm:.3f} Y:{Ym:.3f} Z:{Zm:.3f}",
# (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,255,255), 2)
# 初期値の設定
if (PT0 is None) and (Xm is not None):
PT0 = (Xm, Ym, Zm)
# 差分計算
dX = dY = dZ = None
if (Xm is not None) and (PT0 is not None):
dX = Xm - PT0[0]
dY = Ym - PT0[1]
dZ = Zm - PT0[2]
if found_bbox and (x1 is not None):
cv2.rectangle(color_np, (x1, y1), (x2, y2), (0,255,0), 2)
if Xm is not None and dX is not None:
if hold_mode:
txt1 = f"HOLD dX={dX:+.3f} dY={dY:+.3f} dZ={dZ:+.3f} [m]"
else:
txt1 = f"dX={dX:+.3f} dY={dY:+.3f} dZ={dZ:+.3f} [m]"
txt2 = f"X={Xm:.3f} Y={Ym:.3f} Z={Zm:.3f} [m]"
else:
txt1 = "No valid 3D yet"
txt2 = ""
cv2.putText(color_np, txt1, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (255,255,255), 2)
if txt2:
cv2.putText(color_np, txt2, (10, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (200,200,200), 2)
cv2.putText(color_np, f"t={t_elapsed:.2f}s dt={dt*1000:.1f}ms", (10, 90),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255,255,0), 2)
# CSV記録
if Xm is not None:
wcsv.writerow([f"{t_elapsed:.6f}", f"{dt:.6f}", f"{dX:.6f}", f"{dY:.6f}", f"{dZ:.6f}"])
# 表示
cv2.imshow("YOLOv8 + RealSense", color_np)
if cv2.waitKey(1) & 0xFF == 27:
break
# 動画を保存するため
init_writer_if_needed(color_np, FPS)#color_npにテキストが書かれているので。
video_writer.write(color_np)
finally:
pipe.stop()
cv2.destroyAllWindows()
try:
if video_writer is not None:
video_writer.release()
except Exception:
pass
print(f"CSV saved to: {csv_path}")
検証実験と結果
実際にペンを認識し動きを追えるのかを少し検証した動画を次に示す.(約2倍速)
この時の運動計測結果を図34に示す.
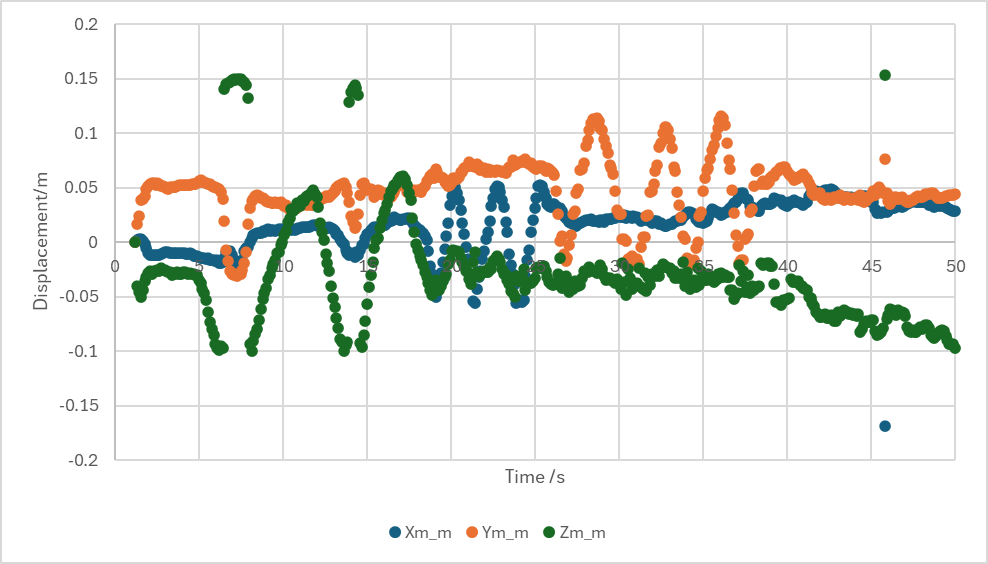
課題
今のコードは安定化のためにバウンディングボックスの中の点群データを取り, その中の深さ情報を比べて中央値の運動を計測している. そのためサンプリング時間が大きくなっている.
バウンディングボックスの中央値を追跡するようにすると, 今よりも高速に動作可能と予測できる.
参考文献
[1]https://docs.ultralytics.com/ja/models/yolov8/ 2025/11/12閲覧
[2]https://docs.ultralytics.com/ja/datasets/detect/#ultralytics-yolo-format 2025/11/12閲覧


{kind=link}
コメント